Insights and resources

Troubleshooting your Microsoft Word Table of Authorities: A Deeper Dive into Field Codes
What happens if a citation doesn’t appear correctly in the TOA? For example, perhaps a pincite or errant ¶ made its way into the citation? Or the same citation appears multiple times? These are all problems that can be fixed by directly editing field codes.

Creating Tables of Authority in Microsoft Word – The 2026 Jurisage Guide
In this series, we’ll take a deep dive into how to use the most common piece of legal technology available today — Microsoft Word — to generate TOAs.
Introducing CiteSense and Legislation 2.0
CiteRight introduces groundbreaking enhancements with CiteSense citation recognition and powerful legislative excerpt management.

Five useful resources for Tables of Authorities
Tables of Authorities are complex, finicky things. Luckily, some really smart people have figured out a number of useful tips, tricks, and best practices to wrestle TOAs into order. Here are a few of the ones we like the best.

How I Handle Tables of Authorities (Without Losing My Mind)
Tables of Authorities often show up when you’re busiest. In this post, I share my practical approach to handling TOAs—simple habits, helpful tools, and lessons learned from balancing deadlines with detail.

Creating Tables of Authorities: What the Options Look Like
Since preparing TOAs isn’t exactly pleasant, there are a lot of tools that aim to automate them. We’ve put together this list of TOA tools to help you understand their pros and cons.
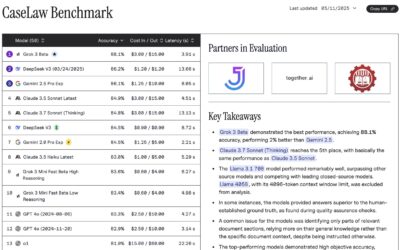
Why Benchmarks are Important — Especially in Law
In a recent blog post, we wrote about Cautious Curiosity as a framework to evaluate the results of content generated by Large Language Models (LLMs). We highlighted the risks of general purpose AI models and how they can hallucinate and provide inconsistent answers,...

Using AI as a collaborative, creative tool
A recent study from Harvard Business School on working alongside LLMs has lessons for lawyers and other professionals who want to leverage AI effectively in our own practices.

Putting legal AI through its paces: An argument for cautious curiosity
Let’s talk about some of the ways that LLMs struggle, and what we can learn about how to integrate AI into our own practices by being mindful of those struggles.

For Legal Teams Evaluating Generative AI, Curiosity is Your Best Asset
The best way to understand and evaluate specialized legal generative AI is to first explore general-purpose AI—not because it works perfectly, but precisely because it doesn’t. Its shortcomings help you identify exactly what domain-specific AI providers are trying to fix.